
お茶情の研究を覗いてみよう
このシリーズでは、情報科学科の学生が行った最先端の研究から、
国際学会で高い評価を得たものを紹介していきます。
第6弾:ふたつのグラフの間柄
紹介論文
シリーズ第6弾で紹介する研究は、中野由加子さんが修士1年のときに行った以下の研究です。
"Yukako Nakano and Ichiro Kobayashi, “Generating a Natural Language Sentence ex- plaining Trends of Two Time-Series Data,"
2023 年 12 月に先進的な知能システムに関する国際会議 ISIS 2022 ISIS 2022 にて発表し、 最優秀論文賞 (The Best Paper Award) を受賞。(中野さんが大学院修士1年のとき。)
概要と背景
いろいろな情報があふれかえっている現代、インターネットには様々な記事やデータが公開されています。なかには詳しく説明しているページもあって、うまいこと必要なページを見つけられれば多くの欲しい情報を得ることができます。一方、単にいろいろなデータが置いてあるだけで、それをどのように解釈したら良いのかわからない場合もあります。専門知識を持った人であれば、現在の気温や天気図の情報を見て、この先の天気を見通すことができそうですが、多くの人にとっては、そもそも情報のどの部分に着目すれば良いのかを判断することも簡単ではないでしょう。
中野さんが取り組んだ研究は、そのようなグラフのデータから、データの動きを説明する文を自動で生成しようというものです。例えば、いろいろな国の気温の推移を表したグラフがあったとき、「夏の時期に気温のピークが来ている」とか「朝方に気温が下がっている」など、数値の動きを言葉で表現してくれるのです。このような説明があると、グラフを上手に読めなくても大体の傾向を理解することができます。また、目の不自由な人に対して音声で説明してあげることもできるようになるでしょう。
データの特徴を言葉で説明する研究は、これまでにもなされてきました。いろいろな種類のグラフやチャートが何の説明をしているのか、例えばどこの国のデータであるとか、これは人口のデータであるとかを説明するものや、もう少し変わった例としては、スポーツの戦況を解説するものなどもあります。皆さんは、本当にその場で実況中継をしてくれるているかのようなゲームをしたことがあるかも知れません。ここでの研究は、そのような実況中継を自動で生成する技術などにもつながっています。
しかし、これまでの研究では、データの増加や減少をとらえられるものはあまり多くありませんでした。さらに、これらはいずれもひとつのデータのみを扱ってきました。例えば、特定の地点の降水量のデータについて「降水量が増えた」といった説明や、川の水位のデータについて「水位が上がった」といった説明をすることはできたとしても、複数のデータが同時に与えられると、それぞれのデータの動きだけでなく、その間の相互関係が生じます。異なるふたつの川の水位のデータがあれば「片方の川の水位が下がる一方で、もう片方の水位は上がった」といった関係が生まれますし、降水量と水位のデータがあれば「降水量が増えるとともに水位も上がった」といった関係がでてきます。これらの相互関係は、それぞれのデータの動きを独立にとらえるだけでは表現できなかったのです。そこで、中野さんはデータの推移を言葉で説明する研究の中でも、特にふたつのデータがどのような関係にあるのかに着目し、それを言葉で説明するための仕組みを研究しました。
学習データの生成
様々に変化するいろいろなデータから、その説明文を生成するというなんとも曖昧な問題に対処するには、このシリーズでこれまでも扱ってきた深層学習の手法を使うのが有効です。つまり、 大量のデータとその特徴を与えて、例えば「値が増加した」というのがどういうことかを学習させようというわけです。しかし、これはそう簡単にはいきません。
ひとつのデータなら、直近の動きを見れば「値が増加した」という特徴を見出せそうです。でも、ふたつのデータだと、片方がこのような動きをしているときにもう片方がどのように動いているのかを把握しなくてはなりません。そのようなことを検出する研究はこれまでにはほとんどありませんでした。
深層学習の手法を試してみようという方針を立てたとしても、学習させるデータをどのように集めるのかも問題です。世の中にはいろいろなグラフデータがあふれてはいますが、それらは「値が増加した」など明確な動きを示しているものはまれで、複雑な動きをしていたり、多数の動きが混ざっていたりします。一般的な教師ありの深層学習では、学習するデータに加えて、それが何を意味するのかを表す「正解文」も一緒に与える必要があります。ですが、そもそも世の中のデータがみな明確な動きを示しているわけではなく、それらに対応した正解文を作るのはとても大変です。
そこで中野さんは、抽出する動きを絞り、その動きをするデータと正解文を自分で作ることにしました。そもそもふたつのデータの関係を抽出するという研究がこれまでになされていないので、何ができるのかを調べるためにも、まずは理想的な状況を作り、そこでできることをはっきりさせようというわけです。特に、ふたつのデータ A と B の関係を見たいので、中野さんは以下の動きを選びました。
- A, B ともに値が増加した
- A, B ともに値が減少した
- A, B ともに値が一時的に高くなってから戻った
- A, B ともに値が一時的に低くなってから戻った
「一時的に高くなってから戻った」という表現は少し長いので、この先では「ピークした」という表現を使います。また、「一時的に低くなってから戻った」の方は「ディップした」と表現することにしましょう。両者の例は、後に出てくる図 1 や図 5 を見てください。
ふたつのデータの関係は協調して動くのではなく背反して動く場合もあります。そこで上の4 つのパターンとは逆の 4 つも採用しました。
- A の値が増加し、B の値は減少した。
- A の値が減少し、B の値は増加した。
- A の値はピークし、B の値はディップした。
- A の値はディップし、B の値はピークした。
このような値の増減に加えて、それらの出来事がいつ起きたのかについても考慮します。値の変化が起きる時期を初期、中期、末期の 3 つに分けて、どの時期に変化が起きたのかも学習できるようにしようというわけです。その上で、これら全てのパターンについて、人工的にグラフを生成しました。
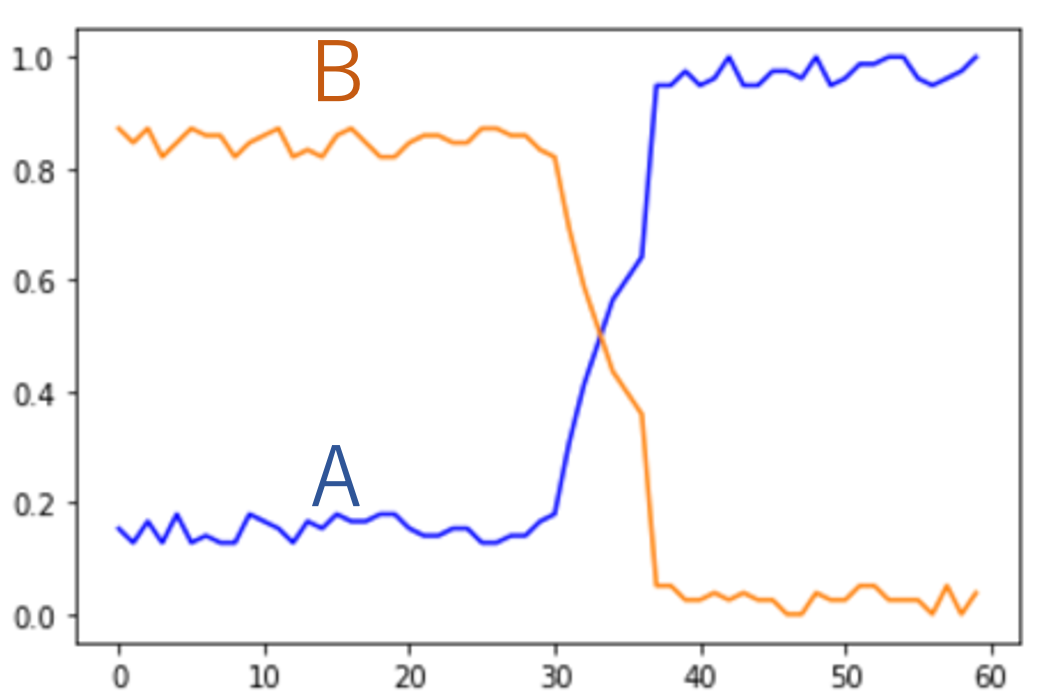
例えば、図 1 は作成したグラフの例です。左のグラフでは、データ A(青)は「中期に値が増加」していますが、データ B(オレンジ)は同じ時期に「値が減少」しています。一方、右のグラフではデータ A もデータ B も「前期にディップ」しています。これらのグラフでは、どちらのデータも同じ時期に値が変化していることに注目しましょう。学習したい値の変化は、このようにふたつのデータが同時期に起こしている場合の変化です。このようなグラフを考えられる全てのパターンについてたくさん作成しました。
これらのグラフに対して、生成したいのは「(いついつの時期)にグラフ A は(このように変 化)しグラフ B は(このように変化)した」という説明文です。ここで、括弧の中が生成したい部分です。最初の時期は「初期」「中期」「末期」のいずれか、また値の変化のところは「増加」「減少」「ピーク」「ディップ」のいずれかです。例えば、図 1 の左の例なら「中期にグラフ A は増加しグラフ B は減少した」、また図 1 の右の例なら「前期にグラフ A はディップしグラフ B はディップした」となります。このような説明文を自動で生成しようというわけです。
図 1 のグラフや生成される説明文は単純だと感じられるかも知れません。実データとは違って、ここでは値の複雑な変化や複数の時期にまたがる変化は考慮されていません。これは、そもそも複数のデータの間の関係を説明するという研究が行われていないため、どのような仕組みで、どのように学習させれば良いのかがわからないためです。いきなり複雑なデータで学習させてしまうと、うまくいかなかった時にその原因がどこにあるのか、学習の方法がまずかったのか、与えたデータが悪かったのかがわからなくなってしまいます。そうではなく、まずは単純なデータで試してみて、段階的にデータの難易度を上げていくことで、着実に進めていこうという意図で、あえて単純な設定を用いています。
エンコーダ・デコーダモデル
学習の際に用いるのは、シリーズ第 3 弾「異常事態発生!」でも出てきたエンコーダ・デコーダモデルです。そのときに示した機械翻訳の図を再掲します。

エンコーダ・デコーダモデルでは、入力の「これはペンです。」という文をエンコーダに通して、この文の本質(あるいは「意味」)をとらえます。入力の意味をとらえられたら、それをデコーダに通して、欲しい形の出力にすることで翻訳を行います。
エンコーダ・デコーダモデルにおける入力は、一般に順番に並んだデータなら何でも受け取ることができます。上の機械翻訳の例では「これはペンです。」という文が入力ですが、これは最初に「これは」という言葉が来て、次に「ペン」がきて、最後に「です。」が来る並んだデータになっています。エンコーダ・デコーダモデルは、このような並んだデータ、時系列データの本質をとらえ、それを別の形に変換してくれるのです。
中野さんは、このエンコーダ・デコーダモデルを使って、グラフデータの説明文を生成することにしました。例えば、まず、ひとつのグラフデータをエンコーダに通したとします。すると、エンコーダは入力のグラフデータの本質、例えば「初期」「値が増加」といったグラフの特徴をとらえます。いったんそのような情報が得られたら、それをデコーダに通すことで「初期に値が増加した。」といった説明文を生成できるだろうというわけです。
アテンションメカニズム
しかし、エンコーダ・デコーダモデルを使うにはひとつ問題があります。中野さんがとらえたい特徴は、ふたつのデータの間の関係です。ひとつのデータなら、これまでのエンコーダ・デコーダモデルを使えばうまくその特徴をとらえられそうです。でも、ふたつのデータをエンコーダ・デコーダモデルに与えるにはどうすれば良いでしょうか。
ふたつのデータの動きをとらえるためには、ふたつのポイントがあります。ひとつは、どのようにデータをモデルに与えるかです。ひとつのデータなら、それをそのまま与えれば良いのですが、ふたつのデータの場合は、それらをどのようにくっつけるのか、あるいは別々に与えるのかなど、いろいろな方法が考えられます。そして、もうひとつのポイントは、ふたつのデータの間の関係をどのようにとらえるかです。ひとつのデータなら単純にその特徴をとらえるだけですが、ふたつのデータの場合は、それらを比較してその間の関係をとらえる必要が出てきます。
これらふたつのポイントに対応して、中野さんはふたつの技術を導入しました。ひとつはエンコーダをふたつにすることです。ふたつのグラフの動きをそれぞれとらえなくてはならないので、それを行うエンコーダを別々に用意したのです。このようにすることで、まずはそれぞれのデータの特徴をとらえることができるようになりました。
さらに、ふたつの間の関係をとらえるために、中野さんはふたつ目の技術、クロスアテンションメカニズムを使うことにしました。アテンションメカニズムというのは、エンコーダで時系列データを扱っているときに、注目すべき重要な部分がどこかを解析する手法です。これまでに用いられてきた手法は自分自身の中に重要な部分を探しに行くセルフアテンションメカニズムです。一方、中野さんが知りたいのは、ふたつのデータの間の関係です。そこで、これまでのセルフアテンションメカニズムに加えて、もう片方のデータの中に重要な部分を探しに行くクロスアテンションメカニズムを採用しました。その様子を図 3 に示します。
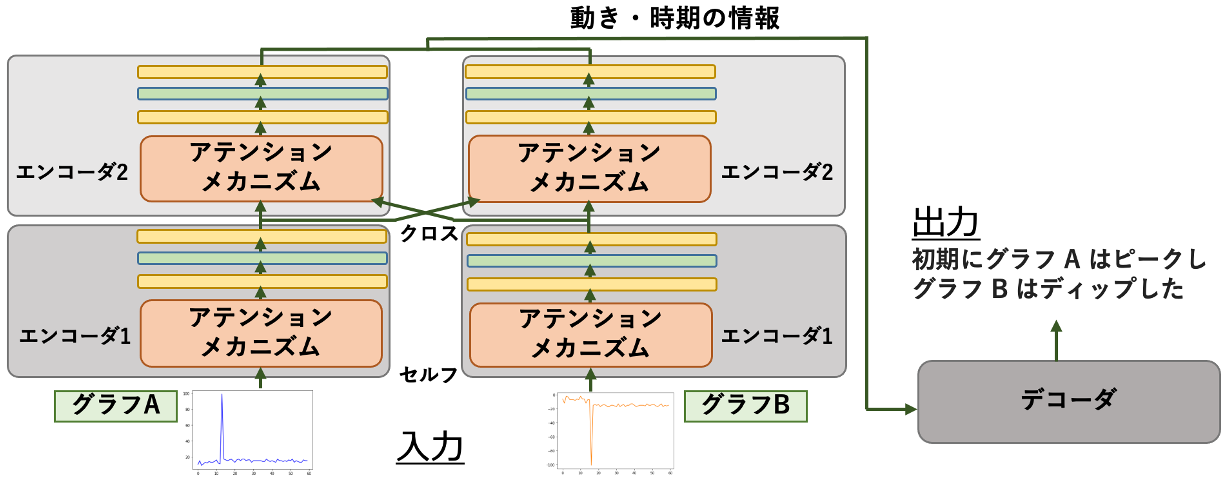
左側の下にあるふたつのエンコーダ 1 がふたつのグラフデータを受け取る部分です。ここで、それぞれのデータを受け取って、別々に解析します。その後、その上にあるエンコーダ 2 の部分で、ふたつのエンコーダ 1 の情報を交差させることで、お互いの関係をとらえられるようにしています。このようにすることで、ふたつの入力を並行して処理しながら、同時期に起きている両者の動きもとらえられるようになっているのです。
一方、デコーダ部分は従来のものから変化はありません。一度、ふたつの入力の間の関係をとらえることができたら、それをこれまでの手法を使って説明文に変換しています。
実験結果
実験は、まず作成したグラフデータを訓練用とテスト用に分けます。訓練用のデータを使って学習を行い、パラメータの値を調整します。その上で、テスト用のデータについて、どの程度、ちゃんとした説明文を生成できるかをチェックします。
結果は、驚くほど良いものでした。ほとんどの場合、ふたつのグラフデータの特徴を正しくとらえて、正解文を生成することができました。理想的な設定で実験したためうまくいったという面もありますが、これまでふたつのグラフデータの間の関係をとらえることはできていなかったので、それがこのようなアプローチで可能であるということがわかったのには大きな意味があります。単純なデータなら増加や減少などの動きをとらえて説明することができることがわかり、ふたつの時系列データの関係を深層学習モデルでとらえて説明をするという試みの第一歩を踏み出すことができました。
追加の実験
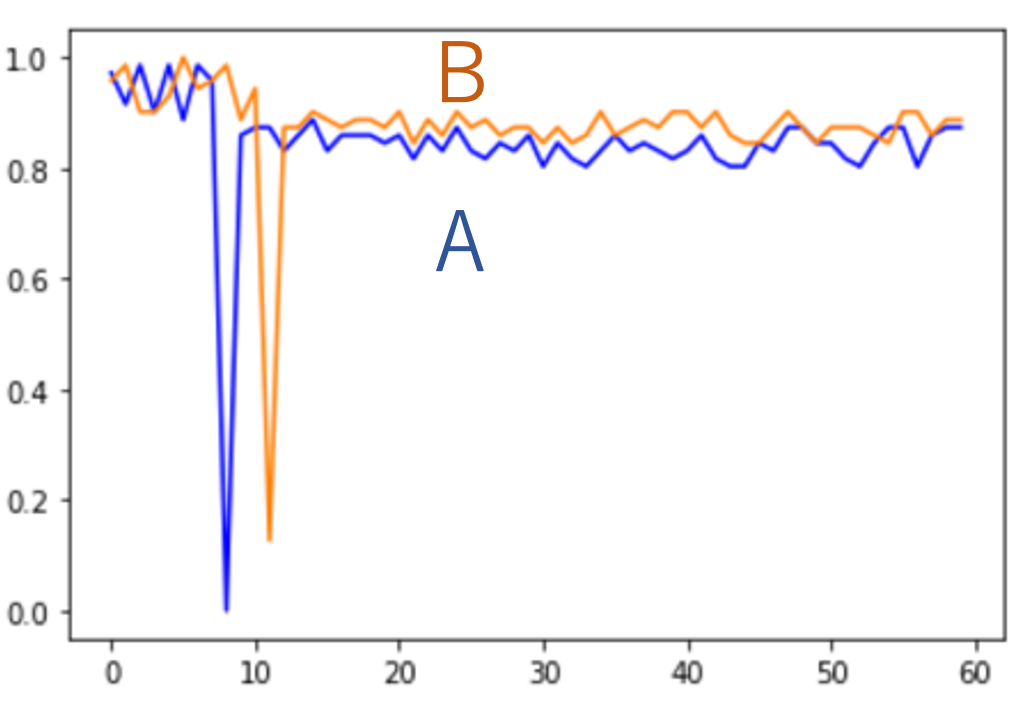
実験結果が非常に優れていたので、中野さんはもうひとつ別の実験を行ってみました。最初の実験で調整したパラメータをそのまま使って、想定されていないデータを入力として与えてみた のです。使用した新しいデータは次の図のようなものです。
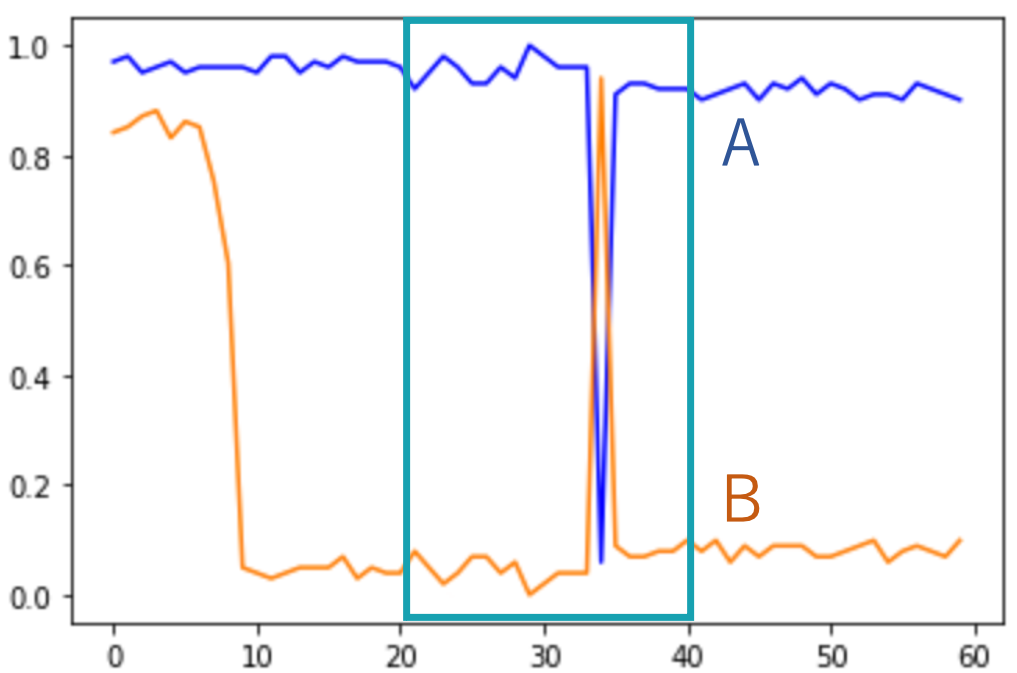
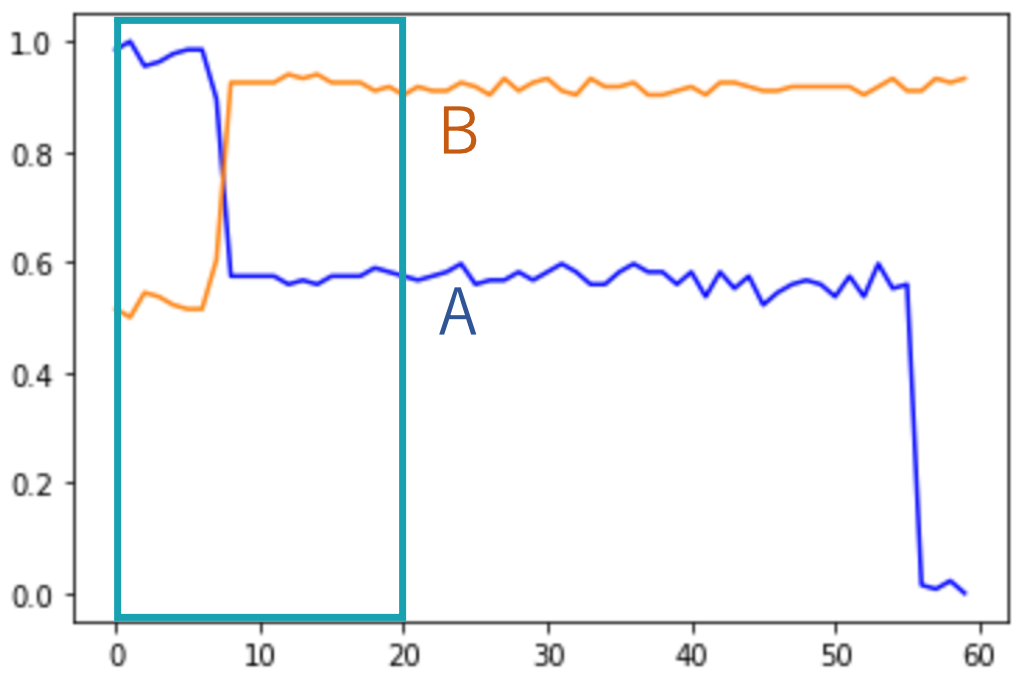
これらのデータには、ふたつのグラフデータが同時に動いているのに加えて、片方のデータが別のところで別の動きをしています。例えば、図 5 の左の図ではどちらも中期に値が動いていますが、加えてオレンジのデータは初期に値が減少しています。今回の研究でとらえたいのは両方のデータが動いているときなので、ここでの正解文は「中期にグラフ A はディップしグラフ B はピークした」になります。同様に、図 5 の右の図では初期にふたつのグラフが同時に変化していますが、加えて青のデータは末期に値が減少しています。ここでも、とらえたいのは初期の同時に起きている変化です。
学習するときに用いたデータは、いずれもふたつのグラフが同時に動いているもののみで、片方が単独で動くような入力は学習させていません。したがって、このようなデータを入れたときにどのような返答をするのかは全くの未知数です。
実際に実験をしてみると、正解文を生成できたのは全体の半分程度になりました。残りの半分については、時期、あるいは動きの記述が間違っていました。実は、図 5 に示したグラフは、どちらも間違った記述を出力してしまった例になっています。図 5 の左のグラフデータでは「初期にグラフ A はディップしグラフ B は減少した」になりました。グラフ A がディップしたという部分は正しいのですが、グラフ B の初期の減少に引っ張られてしまった格好です。また、図 5 の右のグラフデータでは「末期にグラフ A は減少しグラフ B はピークした」になりました。こちらもグラフ A が減少したという部分は正しいのですが、末期でのグラフ A の変化に影響されたのか時期とグラフ B の動きはおかしくなりました。
もう少し詳しく実験結果を調べてみると、エンコーダ、デコーダ両方を通った後の出力文の正解率は半分程度でしたが、動き・時期を指す単語それぞれについて正しい生成文を出力できているかを調べてみると、変化の時期だけについては全体の 7 割程度について、動きについても 75% 程度については正しく抽出できていることがわかりました。動きと時期の両方を同時にとらえられていたのは半分程度にとどまりましたが、片方なら一定の情報を抽出できているのです。
これらの結果は、もともとこのようなデータは学習させていなかったので、うまくいかなかったとしても不思議ではありません。むしろ、学習させていなかったのにも関わらず半分については正解文を生成できた、さらに動きまたは時期については 7 割程度まで正しく認識できていたというのは、この研究で使ったアプローチ、特にアテンションメカニズムの使い方が良く、多少、状況が変わっても対応できるようになっていることを示していると言えそうです。
今後の展望
今回の研究で、これまで手が出なかったふたつのグラフデータの間の関係を抽出できるようになりました。追加実験での結果の改善など、まだ手を加えて行くところはいろいろありますが、 そもそもこのような手法でふたつのグラフデータの間の関係をとらえられることがわかったのが 重要です。方法がわからないと手を出せませんが、一度、方法がわかるとそれを改善していくのは時間をかければできていくものです。その最初の一歩を踏み出せたことが今回の研究の大きな収穫でした。
この研究の上に立って、今後はいろいろな発展が考えられます。ふたつのグラフデータの間の関係を表現できるようになったら次は質問応答なども視野に入ってきます。長いデータの中から「ふたつのデータが同時に増加しているのはどこか」といった問い合わせに対して、その場所を見つけてくることができるかも知れません。また、ふたつのデータを考慮していると、単なる値の増減だけでなく、その程度も気になってきます。グラフ A がグラフ B よりも増加率が大きい場所を探すといったことも可能になるかも知れません。
これらの基礎技術が確立してきたら、いよいよ実データに対しても実験をしていきたいところです。現在、時系列データは社会のありとあらゆる場面で蓄積されています。冒頭に挙げた気象データ以外にも、医療データや株価のデータ、種々の観測データ、またより広く音楽や防犯カメラの映像なども時系列データととらえられます。将来、さまざまな時系列データに対して、その間の関係を自動でわかりやすく説明してくれる日がやってくるかも知れません。
バックナンバー
問い合わせ先
大学へのお問合せはこちらをご覧ください〒112-8610 東京都文京区大塚2-1-1
TEL : 03-5978-5704
FAX : 03-5978-5705
責任者 : 情報科学科HP運営委員会 伊藤貴之

※このウェブサイトは情報科学科の学生によって制作されています。